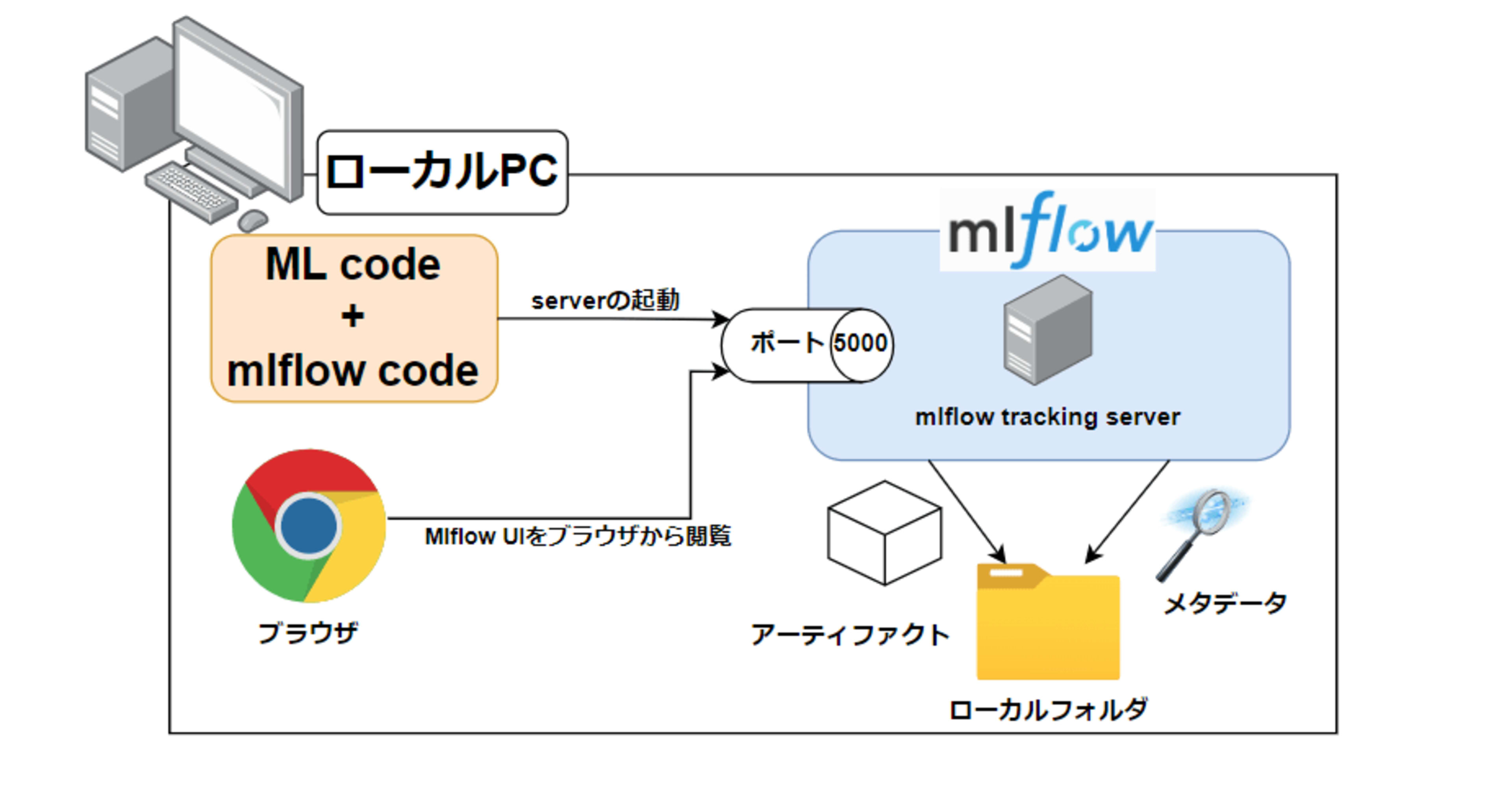
実験管理が簡単に行えるmlflow trackingをローカル環境上で試してみた。
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、ともぞうです。
今回はMLflowについて一部機能(tracking)を紹介させていただきます。
私自身、今まで名前は聞いたことがあったのですが、実際に触ったことは一度もありませんでした。
その為、
- 一体MLflowとは何なのか?
- どんな場面で活躍するのか?
これらを理解したいと強く思ったことが本記事を作成に至ったきっかけとなります。
本記事が同じような境遇の方にぜひ参考になれば幸いです。
対象読者
- MLflowの名前は知っているが、実際に触ったことない方
- 機械学習モデル周りのパラメータ・メトリクス管理に煩わしさを感じている方
※ 既にMLflowのtracking機能を個人で実装したことがあり、それ以外の機能が知りたい方、ないしはそれらを組み合わせてチーム開発に沿った設計・実装方法を知りたい方は対象外となり得ます。
それでは本題に入っていきます。
1. 機械学習ワークフローとは
MLflowを紹介する前に、機械学習ワークフロー(Machine Learning Workflow)についてまず説明させてください。
機械学習ワークフローは、機械学習モデルの開発、トレーニング、評価、デプロイ、および管理のための一連のステップやプロセスを指します。(下図参照)
これらのステップは、データの準備から始まり、最終的にモデルが実運用環境で使用されるまでの一連の活動を含みます。
この機械学習ワークフローが機械学習プロジェクトを効率的に進めるために必要とされているのです。
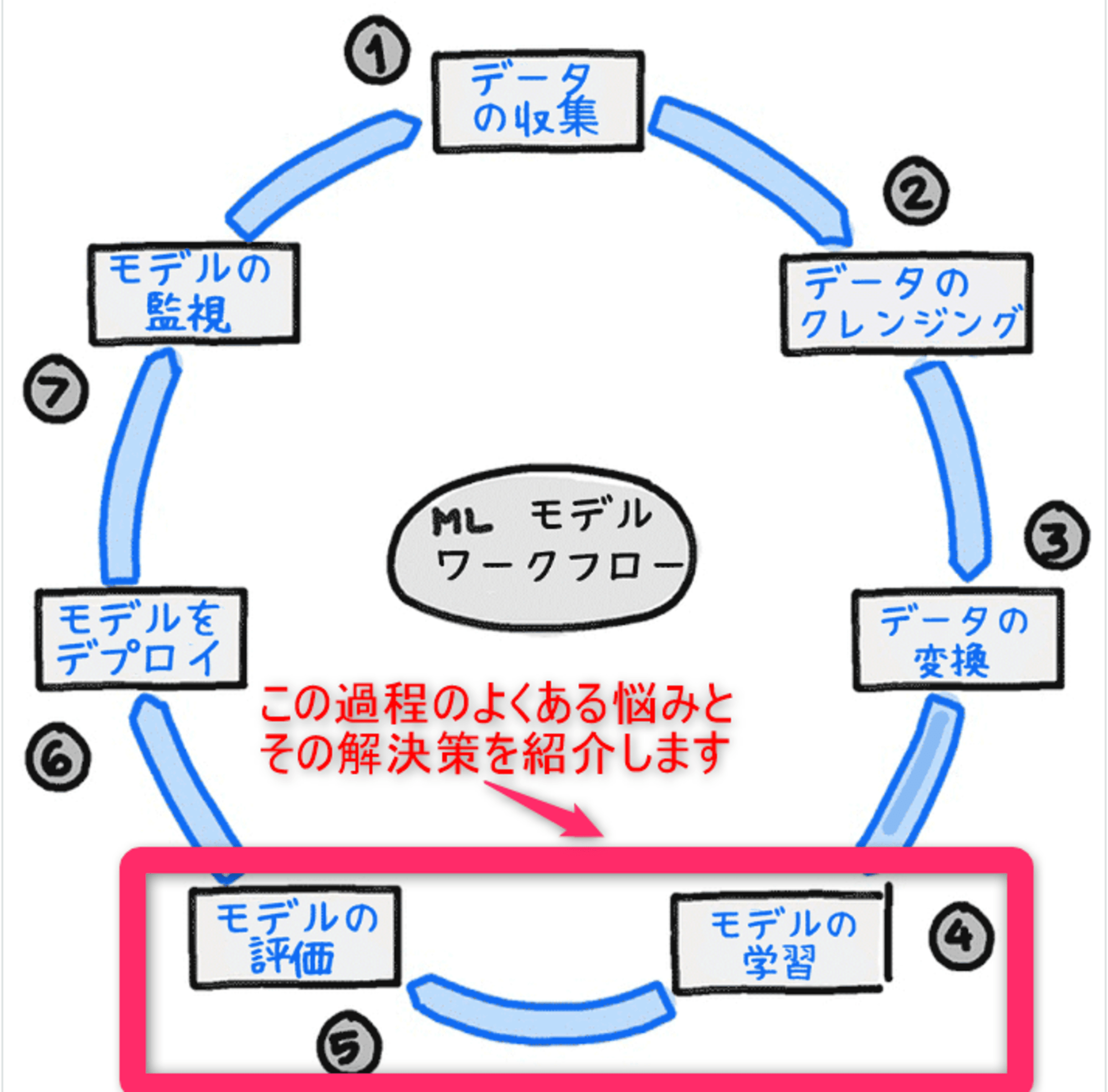
本記事は、上図にある機械学習ワークフローの7ステップの中で、④モデルの学習, ⑤モデルの評価のステップに対してmlflow trackingを用いると運用が大幅にラクになる話をさせていただきます。
2. Mlfowとは
公式ページには以下のように記載されていました。
Stepping into the world of Machine Learning (ML) is an exciting journey, but it often comes with complexities that can hinder innovation and experimentation.
MLflow is a solution to many of these issues in this dynamic landscape, offering tools and simplifying processes to streamline the ML lifecycle and foster collaboration among ML practitioners.
Whether you’re an individual researcher, a member of a large team, or somewhere in between, MLflow provides a unified platform to navigate the intricate maze of model development, deployment, and management. MLflow aims to enable innovation in ML solution development by streamlining otherwise cumbersome logging, organization, and lineage concerns that are unique to model development. This focus allows you to ensure that your ML projects are robust, transparent, and ready for real-world challenges.
Read on to discover the core components of MLflow and understand the unique advantages it brings to the complex workflows associated with model development and management.
一言でいうと、
機械学習ワークフローをラクに実現してくれるツールです!
機械学習プロジェクトに携わるエンジニアの方が実装面・運用面で頭を悩ませているタスクは多々あるかと思います。
そんなとき、こんなツールがあったらな…と思い浮かべたことはありませんか?
その一つがMLflowです!
※MLflowの開発元・提供形態などの基本的な情報を記載しておきます。
2018年にDatabricks社が開発し、OSSのライブラリとして提供しています。
現在も活発にコミュニティによってメンテナンスされています。
Mlflowライブラリは、機械学習を実行するものではないことに注意して下さい。
基本的に機械学習ライブラリ(sklearn, pytorch, tensolflow等)と併用して使うものです。
3. mlflow tracking機能とは
機械学習実験(機械学習モデルの性能を最適化するまでの一連の試行)に関する情報(ArtifactsとMetadata)を追跡・管理(全ての情報を自動的に記録し、体系的に整理することでいつでも見たい情報が確認できる状態に)することができる機能です。
-
Artifactsとは
- モデルファイル(例:
.pklなど) - データセット(学習時や評価時に用いたデータセット 例:
train.csv,valid.csvなど) - プロットやグラフ(学習過程や結果を可視化する画像ファイル 例:
学習曲線,混同行列など) - モデル作成時に用いたソースコード(例:
main.pyなど)
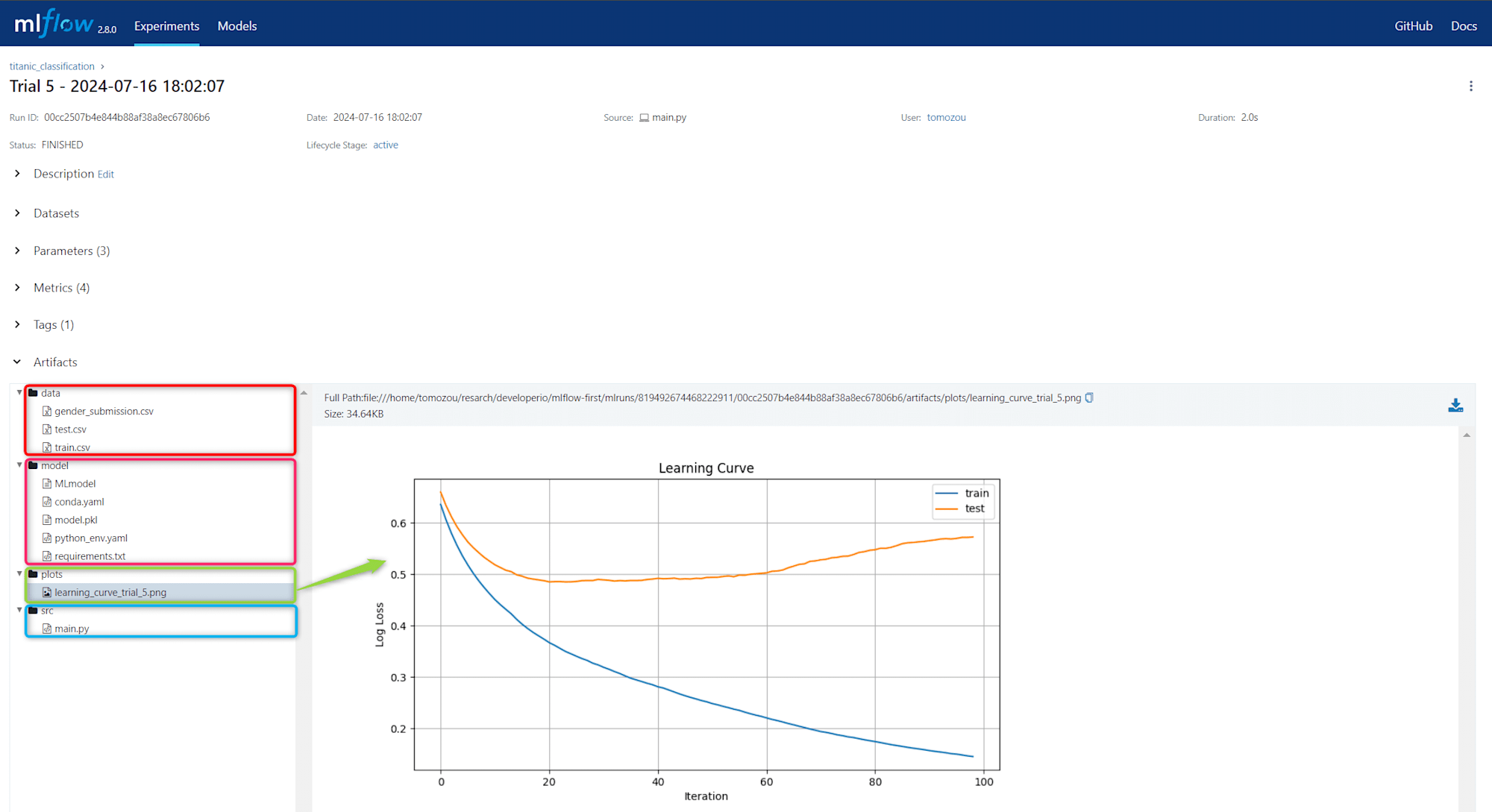
- モデルファイル(例:
-
Metadataとは
- 学習パラメータ(例:
学習率,n_estimators,num_leavesなど) - 精度メトリクス(例:
正答率,F1スコア,再現率など) - モデル学習に関する情報(例:
モデル学習開始時刻,学習実行者など)
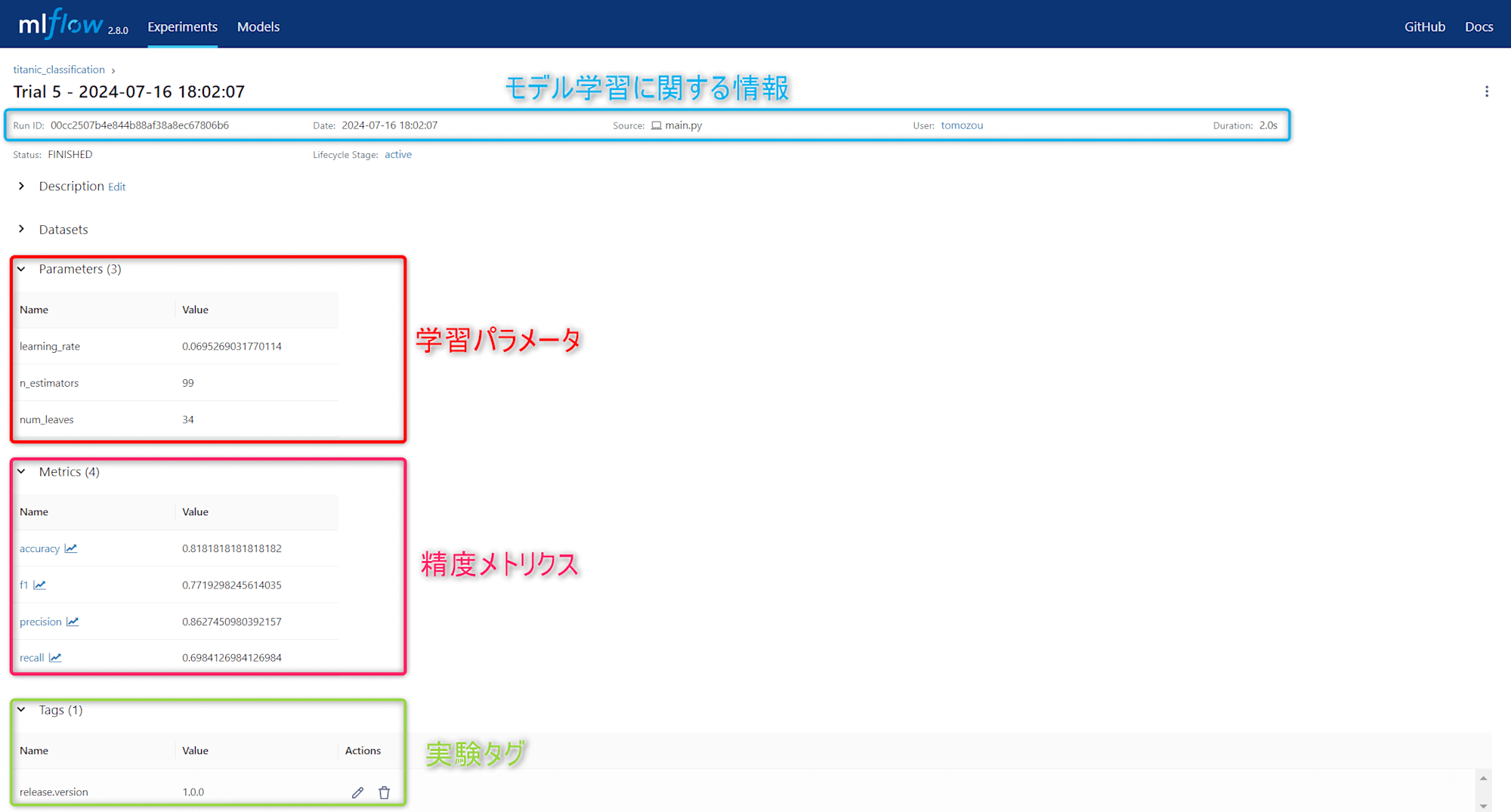
- 学習パラメータ(例:
上図のように、機械学習実験に纏わる情報が自動で記録されることで、手間をかけずに再現性を担保できることは嬉しいです!
また、それまで時間をかけていた管理業務をコアな試行業務に費やせることも嬉しいですね。
4. 実装
それでは、3で紹介した画面をどのように表示させることができたのか、開発環境・ソースコードともに説明させていただきます。
今回は、kaggleコンペにて紹介されているタイタニックデータを元にLightGBMモデルを作成しました。
また、Optunaライブラリを用いて、最適なハイパーパラメータを探索試行を5回行い、それぞれのパラメータ・メトリクス管理がラクになることを確認していきます。
Optunaによる探索は、初期の段階ではランダムにハイパーパラメータを選び、それを元にさらに最適なパラメータを探しにいく挙動になります。そのため、計5回の最終探索結果がそれぞれ異なるハイパーパラメータになり、それぞれに対応するメトリクス結果を容易に比較できることを確認して頂ければと思います。
開発環境
- ホストOS:
Windows11 Pro - 仮想化環境:
WSL2(Ubuntu) - 統合開発環境(IDE):
VSCode
また、今回は以下のようにPipfileにてパッケージ管理をしています。
[[source]]
url = "https://pypi.org/simple"
verify_ssl = true
name = "pypi"
[packages]
pandas = "==2.0.3"
numpy = "==1.24.3"
scikit-learn = "==1.3.0"
lightgbm = "==4.0.0"
mlflow = "==2.8.0"
optuna = "==3.6.1"
[dev-packages]
[requires]
python_version = "3.11"
python_full_version = "3.11.9"
フォルダ構成
├── titanic-mlflow
│ ├── data # 学習/テスト/提出用データ等の保管フォルダ
│ │ ├── gender_submission.csv
│ │ ├── test.csv
│ │ └── train.csv
│ ├── plots # 学習過程や結果を可視化する画像フォルダ
│ └── src # 前処理からモデル構築を実装する.pyフォルダ
│ └── main.py
├── .python-version
├── Pipfile
└── Pipfile.lock
実行スクリプト
import os
import warnings
import sys
from datetime import datetime
import pandas as pd
import numpy as np
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
from sklearn.model_selection import train_test_split
import lightgbm as lgb
from urllib.parse import urlparse
import mlflow
import mlflow.lightgbm
from mlflow.exceptions import MlflowException
from mlflow.models import ModelSignature
from mlflow.types.schema import Schema, ColSpec
from mlflow.types import DataType
import optuna
import matplotlib.pyplot as plt
def eval_metrics(actual, pred):
"""評価指標を計算する関数。
Args:
actual (array-like): 実際の値。
pred (array-like): 予測値。
Returns:
tuple: 正確度、適合率、再現率、F1スコアのタプル。
"""
accuracy = accuracy_score(actual, pred)
precision = precision_score(actual, pred)
recall = recall_score(actual, pred)
f1 = f1_score(actual, pred)
return accuracy, precision, recall, f1
def load_and_preprocess_data(csv_path):
"""データを読み込み、前処理を行う関数。
Args:
csv_path (str): CSVファイルのパス。
Returns:
tuple: 前処理された訓練データとテストデータ。
"""
print(f"Loading data from: {csv_path}")
if not os.path.exists(csv_path):
raise FileNotFoundError(f"ファイルが見つかりません: {csv_path}")
data = pd.read_csv(csv_path)
data = data.drop(['Name', 'Ticket', 'Cabin'], axis=1)
data = data.dropna()
data['Sex'] = data['Sex'].map({'male': 0, 'female': 1})
data['Embarked'] = data['Embarked'].map({'C': 0, 'Q': 1, 'S': 2})
train, test = train_test_split(data, test_size=0.2, random_state=42)
train_x = train.drop(["Survived"], axis=1)
test_x = test.drop(["Survived"], axis=1)
train_y = train["Survived"]
test_y = test["Survived"]
return train_x, test_x, train_y, test_y
def log_mlflow(trial, train_x, train_y, test_x, test_y, base_dir):
"""MLflowにパラメータとメトリクスをログする関数。
Args:
trial (optuna.trial.FrozenTrial): Optunaのトライアルオブジェクト。
train_x (DataFrame): 訓練データの特徴量。
train_y (Series): 訓練データのターゲット。
test_x (DataFrame): テストデータの特徴量。
test_y (Series): テストデータのターゲット。
base_dir (str): ベースディレクトリのパス。
"""
# アクティブなランがある場合は終了する
if mlflow.active_run() is not None:
mlflow.end_run()
run_name = f"Trial {trial.number + 1} - {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}"
with mlflow.start_run(run_name=run_name) as run:
lgbm = lgb.LGBMClassifier(
num_leaves=trial.params["num_leaves"],
learning_rate=trial.params["learning_rate"],
n_estimators=trial.params["n_estimators"],
random_state=42,
force_row_wise=True
)
# 学習曲線のためにevals_resultを使用
evals_result = {}
lgbm.fit(
train_x, train_y,
eval_set=[(train_x, train_y), (test_x, test_y)],
eval_metric='logloss',
callbacks=[lgb.record_evaluation(evals_result)]
)
predicted_survival = lgbm.predict(test_x)
(accuracy, precision, recall, f1) = eval_metrics(test_y, predicted_survival)
print(f"LightGBM model (num_leaves={trial.params['num_leaves']}, learning_rate={trial.params['learning_rate']}, n_estimators={trial.params['n_estimators']}):")
print(" Accuracy: %s" % accuracy)
print(" Precision: %s" % precision)
print(" Recall: %s" % recall)
print(" F1 Score: %s" % f1)
# 学習パラメータと精度メトリックスをTracking
mlflow.log_param("num_leaves", trial.params["num_leaves"])
mlflow.log_param("learning_rate", trial.params["learning_rate"])
mlflow.log_param("n_estimators", trial.params["n_estimators"])
mlflow.log_metric("accuracy", accuracy)
mlflow.log_metric("precision", precision)
mlflow.log_metric("recall", recall)
mlflow.log_metric("f1", f1)
mlflow.set_tag("release.version", "1.0.0")
# アーティファクトのログ
mlflow.log_artifact(os.path.join(base_dir, "../data/train.csv"), "data")
mlflow.log_artifact(os.path.join(base_dir, "../data/test.csv"), "data")
mlflow.log_artifact(os.path.join(base_dir, "../data/gender_submission.csv"), "data")
mlflow.log_artifact(os.path.join(base_dir, "../src/main.py"), "src")
# モデルスキーマの定義
input_schema = Schema([
ColSpec(DataType.integer, "Pclass"),
ColSpec(DataType.float, "Age"),
ColSpec(DataType.integer, "SibSp"),
ColSpec(DataType.integer, "Parch"),
ColSpec(DataType.float, "Fare"),
ColSpec(DataType.integer, "Sex"),
ColSpec(DataType.integer, "Embarked")
])
output_schema = Schema([ColSpec(DataType.integer, "Survived")])
signature = ModelSignature(inputs=input_schema, outputs=output_schema)
# モデルの保存
mlflow.lightgbm.log_model(lgbm, "model", signature=signature)
print("Model saved in run %s" % mlflow.active_run().info.run_uuid)
# 学習曲線のプロット
plt.figure(figsize=(10, 5))
plt.plot(evals_result['training']['binary_logloss'], label='train')
plt.plot(evals_result['valid_1']['binary_logloss'], label='test')
plt.xlabel('Iteration')
plt.ylabel('Log Loss')
plt.title('Learning Curve')
plt.legend()
plt.grid(True)
# 学習曲線の保存
plots_dir = os.path.join(base_dir, "../plots")
os.makedirs(plots_dir, exist_ok=True)
learning_curve_path = os.path.join(plots_dir, f"learning_curve_trial_{trial.number + 1}.png")
plt.savefig(learning_curve_path)
mlflow.log_artifact(learning_curve_path, "plots")
plt.close()
# ランを終了
mlflow.end_run()
def objective(trial, train_x, train_y, test_x, test_y):
"""Optunaの目的関数。
Args:
trial (optuna.trial.Trial): Optunaのトライアルオブジェクト。
train_x (DataFrame): 訓練データの特徴量。
train_y (Series): 訓練データのターゲット。
test_x (DataFrame): テストデータの特徴量。
test_y (Series): テストデータのターゲット。
Returns:
float: 負の正確度。
"""
num_leaves = trial.suggest_int("num_leaves", 20, 50)
learning_rate = trial.suggest_float("learning_rate", 0.01, 0.1)
n_estimators = trial.suggest_int("n_estimators", 50, 200)
lgbm = lgb.LGBMClassifier(
num_leaves=num_leaves,
learning_rate=learning_rate,
n_estimators=n_estimators,
random_state=42,
force_row_wise=True
)
lgbm.fit(train_x, train_y)
predicted_survival = lgbm.predict(test_x)
accuracy, precision, recall, f1 = eval_metrics(test_y, predicted_survival)
# Optunaは目的関数が最小化されるように設計されているため、負の精度を返す
return -accuracy
def main():
"""メイン関数。データの前処理、Optunaによるハイパーパラメータ最適化、MLflowによるログ記録を行う。
"""
warnings.filterwarnings("ignore")
np.random.seed(40)
# トラッキングサーバの場所
tracking_uri = mlflow.get_tracking_uri()
print('Current tracking uri: {}'.format(tracking_uri))
# レジストリサーバの場所
mr_uri = mlflow.get_registry_uri()
print('Current model registry uri: {}'.format(mr_uri))
# Artifactストレージの場所
artifact_uri = mlflow.get_artifact_uri()
print('Current artifact uri: {}'.format(artifact_uri))
# スクリプトのディレクトリを基準にパスを解決
base_dir = os.path.abspath(os.path.dirname(__file__))
csv_path = os.path.join(base_dir, "../data/train.csv") # Titanicデータのパスを指定
# デバッグのためにファイルパスを出力
print(f"Loading data from: {csv_path}")
train_x, test_x, train_y, test_y = load_and_preprocess_data(csv_path)
experiment_name = "titanic_classification"
try:
# 指定された名前の新しい実験を作成
mlflow.create_experiment(experiment_name)
mlflow.set_experiment(experiment_name)
print(f"Experiment '{experiment_name}' created.")
except MlflowException as e:
# 実験が既に存在する場合はその実験を設定
if "already exists" in str(e):
mlflow.set_experiment(experiment_name)
print(f"Experiment '{experiment_name}' already exists. Set the existing experiment.")
else:
# その他の MlflowException が発生した場合は再スロー
raise
study = optuna.create_study(direction="maximize")
study.optimize(lambda trial: objective(trial, train_x, train_y, test_x, test_y), n_trials=5)
best_trial = study.best_trial
print(f"Best trial: {best_trial.params}")
for trial in study.trials:
log_mlflow(trial, train_x, train_y, test_x, test_y, base_dir)
if __name__ == "__main__":
main()
実行スクリプトの解説
長々と書いてしまっていますが、上記のmain.pyは5つの関数から構成されています。
- ①
eval_metrics - ②
load_and_preprocess_data - ③
objective
以上3つの関数に関しては、MLflow特有のコードではなく、よくある機械学習コードが記述されているので説明を一部省略させていただきます。
機械学習部分
①eval_metrics
概要
評価指標を計算する関数。
1. 正確度 (Accuracy)
2. 適合率 (Precision)
3. 再現率 (Recall)
4. F1スコア (F1 Score)
②load_and_preprocess_data
概要
データを読み込み、前処理を行う関数。
1. データの読み込み。
2. 不要な列の削除 (Name, Ticket, Cabin)。
3. 欠損値の削除。
4. カテゴリカル変数 (Sex, Embarked) の数値変換。
5. 訓練データとテストデータに分割。
③objective
概要
Optunaの目的関数。
1. ハイパーパラメータのサンプリング。
2. LightGBMモデルの学習と評価。
3. 評価指標(正確度)の計算。
4. 負の正確度を返す(Optunaは目的関数が最小化されるように設計されているため)。
MLflow部分
一方、下記二つの関数についてはMLflow特有のコードが絡んでくるため説明させていただきます。
- ④
log_mlflow - ⑤
main
④log_mlflow
概要
MLflowにパラメータとメトリクスをログする関数。
1. アクティブなランがある場合は終了。
2. 新しいランを開始し、モデルの学習と評価を実行。
3. 学習結果と評価指標をMLflowにログ。
4. 学習曲線のプロットを作成し、保存。
5. モデルとそのスキーマをMLflowに保存。
# アクティブなランがある場合は終了する
if mlflow.active_run() is not None:
mlflow.end_run()
「アクティブなランがある場合終了する」という処理は、新しいランを開始する前に前のランを適切に終了することで、MLflowのラン管理を正しく行うためのものです。
(※MLflowのランは、機械学習の実験やトレーニングの一連のプロセスのことで、今回は計5回のランを実行しています。)
これによって、データの混乱を防ぎ、各ランの結果を正確に追跡することができます。
run_name = f"Trial {trial.number + 1} - {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}"
with mlflow.start_run(run_name=run_name) as run:
lgbm = lgb.LGBMClassifier(
num_leaves=trial.params["num_leaves"],
learning_rate=trial.params["learning_rate"],
n_estimators=trial.params["n_estimators"],
random_state=42,
force_row_wise=True
)
# 学習曲線のためにevals_resultを使用
evals_result = {}
lgbm.fit(
train_x, train_y,
eval_set=[(train_x, train_y), (test_x, test_y)],
eval_metric='logloss',
callbacks=[lgb.record_evaluation(evals_result)]
)
predicted_survival = lgbm.predict(test_x)
(accuracy, precision, recall, f1) = eval_metrics(test_y, predicted_survival)
print(f"LightGBM model (num_leaves={trial.params['num_leaves']}, learning_rate={trial.params['learning_rate']}, n_estimators={trial.params['n_estimators']}):")
print(" Accuracy: %s" % accuracy)
print(" Precision: %s" % precision)
print(" Recall: %s" % recall)
print(" F1 Score: %s" % f1)
- ランの開始:
mlflow.start_run(run_name=run_name)を呼び出して新しいランを開始します。 - コンテキストの管理:
with ステートメントを使用することで、ランの開始から終了までのコンテキストを管理します。このブロック内で行われる操作は、すべてこのランに関連付けられます。 - ランオブジェクトの取得:
as runにより、ランオブジェクトをrunという名前で使用できるようにします。 - ランの終了:
with ブロックを抜けると、自動的にランが終了します。これにより、リソースのクリーンアップが確実に行われます。
※ランの名前を指定しない場合、適当な名前が割り当てられます。しかし、実際にそのようにすると各ランを識別・管理するのが難しかったため、今回は Trial 5 - 2024-07-16 18:02:07ような命名規則にしています。
# 学習パラメータと精度メトリックスをTracking
mlflow.log_param("num_leaves", trial.params["num_leaves"])
mlflow.log_param("learning_rate", trial.params["learning_rate"])
mlflow.log_param("n_estimators", trial.params["n_estimators"])
mlflow.log_metric("accuracy", accuracy)
mlflow.log_metric("precision", precision)
mlflow.log_metric("recall", recall)
mlflow.log_metric("f1", f1)
mlflow.set_tag("release.version", "1.0.0")
# アーティファクトのログ
mlflow.log_artifact(os.path.join(base_dir, "../data/train.csv"), "data")
mlflow.log_artifact(os.path.join(base_dir, "../data/test.csv"), "data")
mlflow.log_artifact(os.path.join(base_dir, "../data/gender_submission.csv"), "data")
mlflow.log_artifact(os.path.join(base_dir, "../src/main.py"), "src")
-
mlflow.log_param:モデルのハイパーパラメータをMLflowにログするための関数。この関数は、指定されたパラメータ名とその値をMLflowのランにログします。これによって、後で実験結果を再現するために使用されたパラメータを確認できます。(以下は引数。)- key:パラメータの名前
- value:パラメータの値
-
mlflow.log_metric:モデルの評価指標(メトリクス)をMLflowにログするための関数。この関数は、指定されたメトリクス名とその値をMLflowのランにログします。これにより、モデルの性能を評価するための指標を保存できます。(以下は引数。)- key:メトリクスの名前
- value:メトリクスの値
-
mlflow.set_tag:ランにタグを設定するための関数。この関数は、指定されたタグ名とその値をMLflowのランに設定します。タグはランに関する追加情報を付与するために使用されます。(以下は引数。)- key:タグの名前
- value:タグの値
-
mlflow.log_artifact:ファイルやディレクトリをMLflowのアーティファクトとしてログするための関数。この関数は、指定されたローカルファイルやディレクトリをMLflowのアーティファクトとして保存します。アーティファクトはモデルのトレーニングに使用したデータやスクリプト、生成されたプロットなどを含むことができます。(以下は引数。)- local_path:ローカルファイルまたはディレクトリのパス
- artifact_path:アーティファクトの保存先ディレクトリ。デフォルトはランのルートディレクトリ
# 学習曲線のプロット
plt.figure(figsize=(10, 5))
plt.plot(evals_result['training']['binary_logloss'], label='train')
plt.plot(evals_result['valid_1']['binary_logloss'], label='test')
plt.xlabel('Iteration')
plt.ylabel('Log Loss')
plt.title('Learning Curve')
plt.legend()
plt.grid(True)
# 学習曲線の保存
plots_dir = os.path.join(base_dir, "../plots")
os.makedirs(plots_dir, exist_ok=True)
learning_curve_path = os.path.join(plots_dir, f"learning_curve_trial_{trial.number + 1}.png")
plt.savefig(learning_curve_path)
mlflow.log_artifact(learning_curve_path, "plots")
plt.close()
mlflow.log_artifactは既に説明済みなので省略します。
# モデルスキーマの定義
input_schema = Schema([
ColSpec(DataType.integer, "Pclass"),
ColSpec(DataType.float, "Age"),
ColSpec(DataType.integer, "SibSp"),
ColSpec(DataType.integer, "Parch"),
ColSpec(DataType.float, "Fare"),
ColSpec(DataType.integer, "Sex"),
ColSpec(DataType.integer, "Embarked")
])
output_schema = Schema([ColSpec(DataType.integer, "Survived")])
signature = ModelSignature(inputs=input_schema, outputs=output_schema)
# モデルの保存
mlflow.lightgbm.log_model(lgbm, "model", signature=signature)
print("Model saved in run %s" % mlflow.active_run().info.run_uuid)
-
ModelSignature:モデルの入力および出力のスキーマを定義するクラス。スキーマは、モデルが受け取る「データの形式」や「型」を指定するために使用されます。- inputs:モデルの入力スキーマ
- outputs:モデルの出力スキーマ
-
mlflow.lightgbm.log_model:LightGBMモデルをMLflowに保存するための関数。
この関数は、指定されたLightGBMモデルをMLflowに保存します。signature を指定することで、モデルの入力および出力のスキーマを定義できます。(以下は引数。)- lgb_model:保存するLightGBMモデル
- artifact_path:モデルを保存するアーティファクトのパス
- signature:モデルの入力および出力のスキーマ
⑤main
概要
メイン関数。データの前処理、Optunaによるハイパーパラメータ最適化、MLflowによるログ記録を行う。
1. ランダムシードの設定。
2. MLflowのトラッキングURI、モデルレジストリURI、アーティファクトURIの取得と表示。
3. データの読み込みと前処理。
4. MLflow実験の作成または設定。
5. Optunaによるハイパーパラメータ最適化の実行。
6. 各トライアルの結果をMLflowにログ。
np.random.seed(40)
main 関数内で np.random.seed(40) を設定することで、以下のような操作の再現性を確保しています。
-
データの前処理と分割
load_and_preprocess_data関数内で、データのシャッフルやトレイン・テスト分割が行われる場合、その結果が毎回同じになります。具体的には、train_test_split関数が乱数を使用してデータを分割するため、この部分での再現性が確保されます。 -
Optunaによるハイパーパラメータ最適化
Optunaのハイパーパラメータ探索は内部で乱数を使用するため、シードを設定することで探索結果が再現可能になります。
# トラッキングサーバの場所(実験結果が保存されるサーバ)
tracking_uri = mlflow.get_tracking_uri()
print('Current tracking uri: {}'.format(tracking_uri))
# レジストリサーバの場所(モデルが登録されるサーバ)
mr_uri = mlflow.get_registry_uri()
print('Current model registry uri: {}'.format(mr_uri))
# Artifactストレージの場所(トレーニングデータやモデルファイルなどが保存されるストレージ)
artifact_uri = mlflow.get_artifact_uri()
print('Current artifact uri: {}'.format(artifact_uri))
MLflowの各コンポーネントがどこに配置されているかを明確に把握できます。
今回はMLflowに慣れることを目的にしていたため、すべてローカルホスト上での検証をしています。
# スクリプトのディレクトリを基準にパスを解決
base_dir = os.path.abspath(os.path.dirname(__file__))
csv_path = os.path.join(base_dir, "../data/train.csv") # Titanicデータのパスを指定
# デバッグのためにファイルパスを出力
print(f"Loading data from: {csv_path}")
train_x, test_x, train_y, test_y = load_and_preprocess_data(csv_path)
機械学習部分であるため説明を省略します。
experiment_name = "titanic_classification"
try:
# 指定された名前の新しい実験を作成
mlflow.create_experiment(experiment_name)
mlflow.set_experiment(experiment_name)
print(f"Experiment '{experiment_name}' created.")
except MlflowException as e:
# 実験が既に存在する場合はその実験を設定
if "already exists" in str(e):
mlflow.set_experiment(experiment_name)
print(f"Experiment '{experiment_name}' already exists. Set the existing experiment.")
else:
# その他の MlflowException が発生した場合は再スロー
raise
MLflowを使用して実験の管理を行うために設定しています。
今回は、計5回のランをtitanic_classificationという実験名で管理していることになります。
study = optuna.create_study(direction="maximize")
study.optimize(lambda trial: objective(trial, train_x, train_y, test_x, test_y), n_trials=5)
best_trial = study.best_trial
print(f"Best trial: {best_trial.params}")
機械学習部分であるため説明を省略します。
for trial in study.trials:
log_mlflow(trial, train_x, train_y, test_x, test_y, base_dir)
既にlog_mlfowは既に説明済みなので省略します。
WSL上でのコマンド操作
python titanic-mlflow/src/main.py
上記のコマンドを実行すると、
titanic-mlflowフォルダーと同じ階層にmlrunsディレクトリが作成されます。
mlrunsディレクトリには、各実験のパラメータ、メトリクス、アーティファクト、モデルなどが含まれます。
これらの結果を視覚的に確認したいと思います。
mlflow ui
上記のコマンドを実行し、ブラウザで http://127.0.0.1:5000 にアクセスすると、MLflowのUI画面が表示されます。
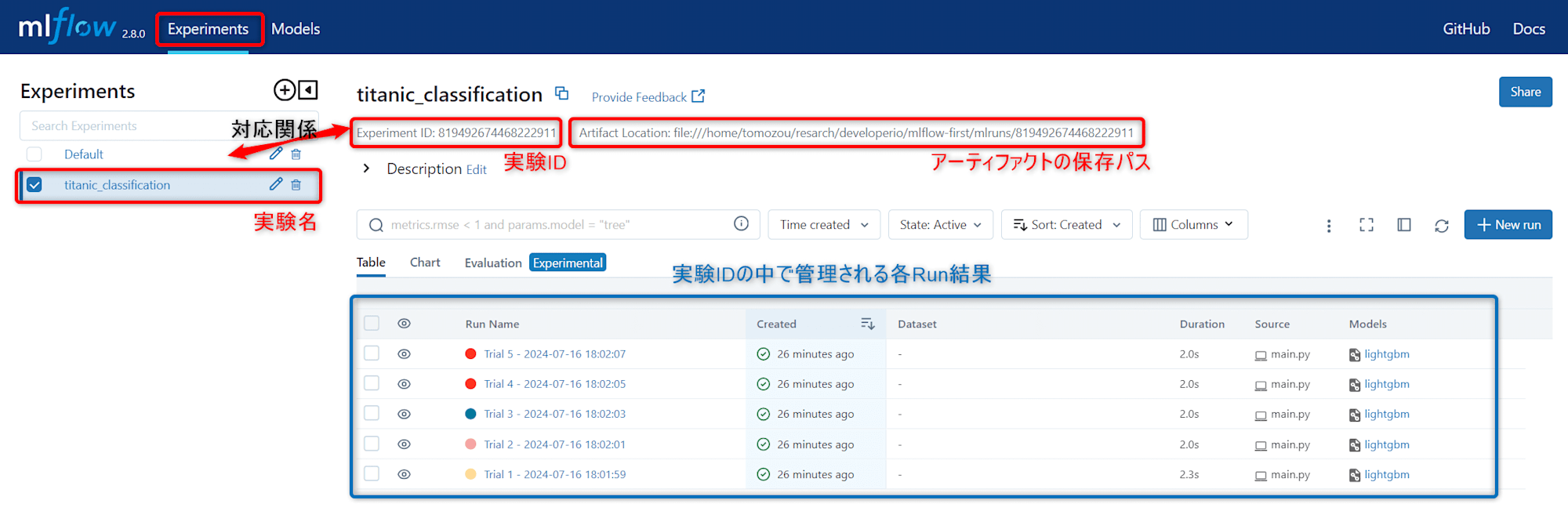
各ランの実行結果が表示されました!
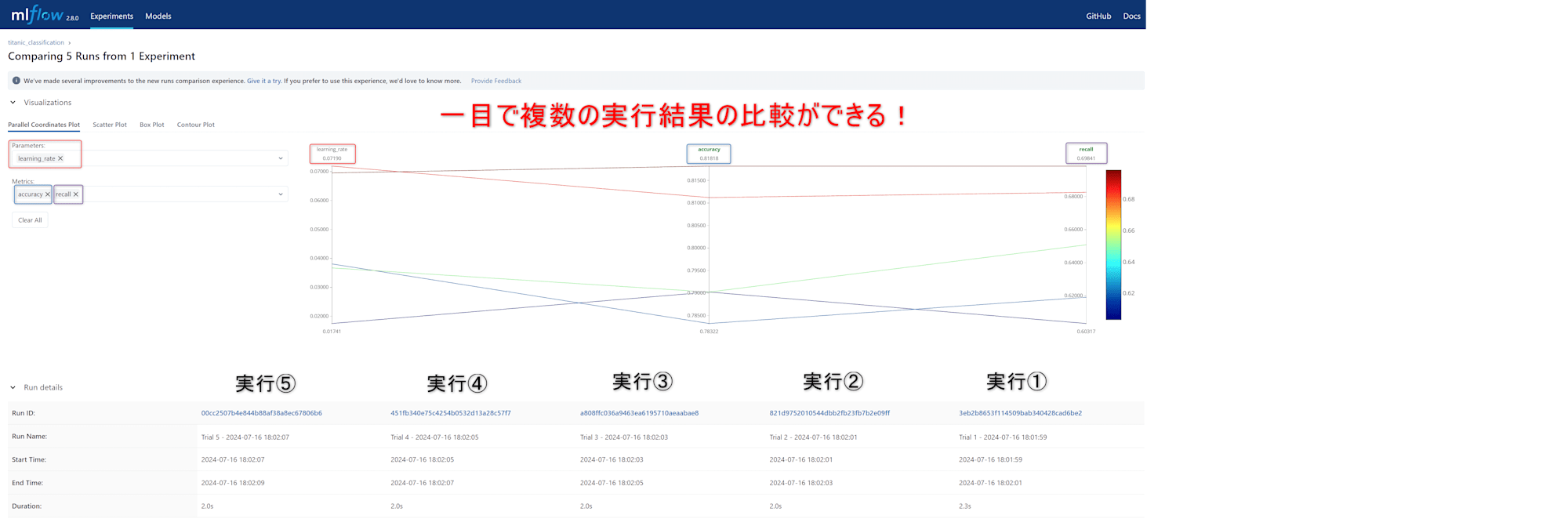
また、各ランの左にある「□」をクリックした後、「Compare」をクリックすると、以下のように各ランのメトリクスを容易に比較することができます!
5. 個人的に感動したことTop2
1位:そもそもMLflowの設定が簡単である
便利なツールが登場したとしてもそのセットアップが複雑な場合、それだけで挫折してしまう場面がありました…
しかしMLflowは環境構築も容易で、機械学習コードを書き換えることなく、数行MLflowのコードを追加するだけで設定ができてしまうことに一番感動しました。
- MLflowを利用するためには
pipコマンドでインストールするだけ。
pip install mlflow
- 実験のトラッキングするには、数行のコードを追加するだけでok。
今までのスクリプトは、MLflowの機能を紹介するために長くなってしまいましたが、以下のようなスクリプトでスモールスタートできることも魅力的です!
import mlflow # 追加
import mlflow.sklearn # 追加
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# データの読み込み
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=42)
# MLflowのランを開始
with mlflow.start_run(): # 追加
# モデルのトレーニング
clf = RandomForestClassifier(n_estimators=100, random_state=42)
clf.fit(X_train, y_train)
# 予測と評価
predictions = clf.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
# パラメータとメトリクスをログ
mlflow.log_param("n_estimators", 100) # 追加
mlflow.log_metric("accuracy", accuracy) # 追加
# モデルをログ
mlflow.sklearn.log_model(clf, "model") # 追加
print(f"Model accuracy: {accuracy}")
2位:モデルの入力・出力のスキーマを定義するだけで自動でドキュメント化してくれる
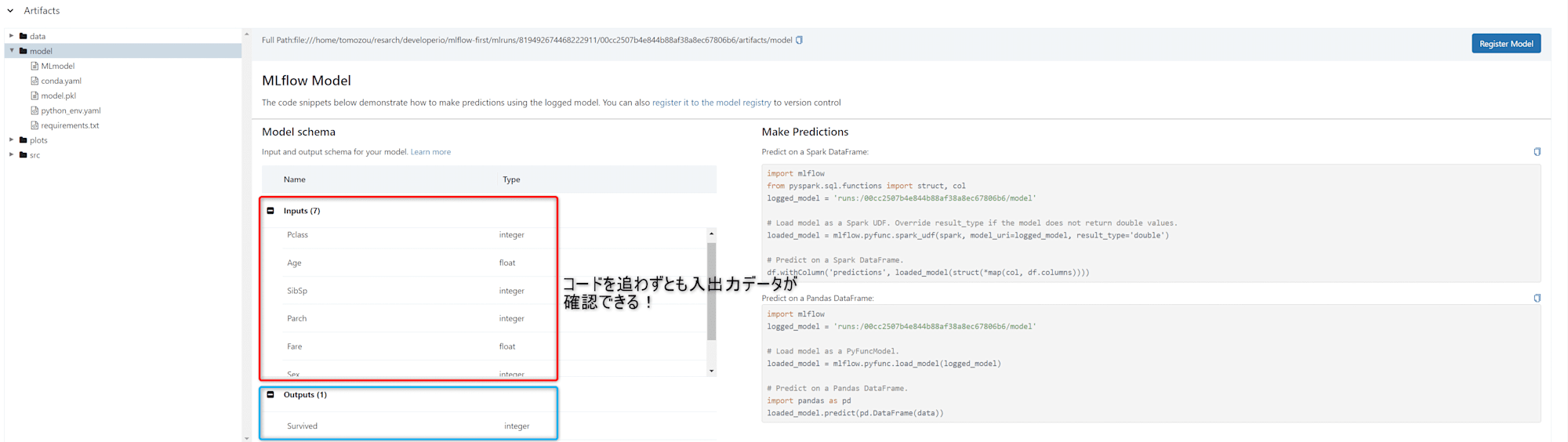
ハイパーパラメータやメトリクスを自動で見やすく管理できることに対しても感動していました。更に説明変数と目的変数のスキーマ(カラム名・型名)まで容易に自動管理できることにはびっくりしました!
これによって、他の開発者やデータサイエンティストがモデルを再利用する際に、データの準備や前処理が容易になることは嬉しいです!
6. 所感と今後の展望
本記事の構成とローカルデータベースを想定した構成は、localhost上でのアクセスに限定されています。
言い換えれば、開発者本人のPC以外からはアクセスできません。
ですが、個人でコンペに参加したり、開発をする分には本記事の構成で十分適していると感じました。
また、個人開発ではなく、チーム開発上で実験記録を多くのメンバーと共有する場面が訪れる場合は、Mlflow Tracking Serverをリモート上に配置することが求められると思います。
それに伴い、メタデータの保管場所をデータベース(例:SQLite, MySQL, PostgreSQL)、アーティファクトの保管場所をクラウドストレージ(例:AWS S3, Google Cloud Storage等)にする必要性もあります。
実務の機械学習プロジェクトはチーム開発がメインだと思いますので、次回はチーム開発を見据えた構成を紹介できればと思います。






